優化器(Optimizer)是機器學習中用於調整模型參數以最小化損失函數。如果覺得太複雜,就記得那些最常用的SGD及Adam就可以了,剩下就當作多認識的!常見的優化器種類:
梯度下降法(Gradient Descent):梯度下降是最基本的優化算法之一,我們在Day14有介紹過,其中又可以細分為:
Nesterov動量優化器(Momentum Optimizer):動量優化器是梯度下降的變體,它引入了動量項,有助於克服梯度下降中的局部極小值問題,加速收斂。動量優化器(Momentum Optimizer)在深度學習中的作用是加速收斂,有助於克服損失函數表面上的平緩區域或局部極小值。
AdaGrad:全名為Adaptive Gradient Algorithm,也就是自適應梯度演算法。AdaGrad的好處是會根據每個參數的過去梯度調整學習率,對於不同參數具有不同的學習率。
RMSProp:RMSProp是AdaGrad的變體,它使用移動平均來調整學習率,以平滑學習過程中的梯度變化。
Adadelta:Adadelta是另一種自適應學習率的優化器,類似於RMSProp,但它不需要手動調整學習率。
Adam(Adaptive Moment Estimation):Adam是一種結合了動量和RMSProp的優化器,也可以說是所有優化器集大成。廣泛用於深度學習中,通常具有很好的性能。
這僅僅是一些常見的優化器,還有許多其他優化器和它們的變體,每種優化器都有優點跟缺點,適用的地方也不同,取決於問題的特性,可以多加嘗試不同優化器,看模型做適合哪種。
接下來我們就要繼續升級神經網路啦~
我們拿之前之前打好的程式碼在匯入模組的地方繼續往裡面import Dropout跟BatchNormalization就可以了
#匯入模組
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout #加入丟棄法(Dropout)
from tensorflow.keras.layers import BatchNormalization #加入批次正規化
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import SGD
下面這一段都與之前一樣沒有加入新東西
#下載MNIST資料集
(X_train, y_train), (X_test, y_test)=mnist.load_data()
#資料預處理
X_train=X_train.reshape(60000, 784).astype('float32')
X_test=X_test.reshape(10000, 784).astype('float32')
X_train /= 255
X_test /= 255
#標籤預處理 :
y_train=to_categorical(y_train, 10)
y_test=to_categorical(y_test, 10)
在構建神經網路的地方我們在之前的基礎上增加兩層隱藏層,使用批次正規化,並且在最後一個隱藏層添加丟棄層
#建構神經網路
model = Sequential()
#輸入層+第一隱藏層
model.add(Dense(64, activation='relu', input_shape=(784,)))
model.add(BatchNormalization())
#第二隱藏層
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization())
#第三隱藏層
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization()) #批次正規化
model.add(Dropout(0.2)) #每批次隨機丟棄此層 20% (1/5)神經元
#輸出層
model.add(Dense(10, activation='softmax'))
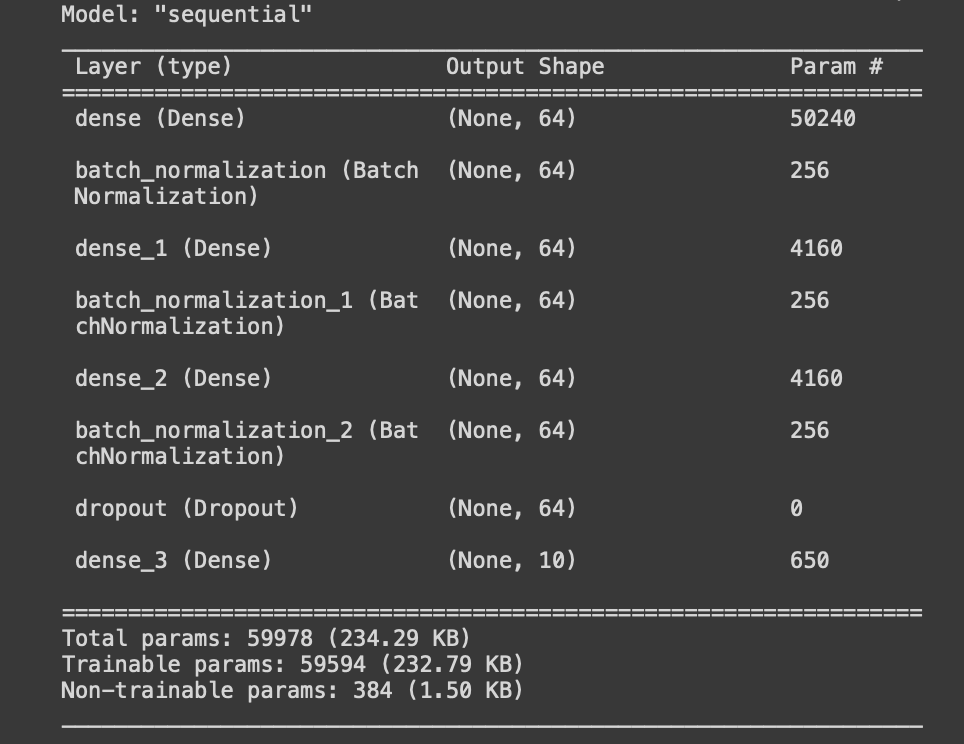
做完後我們可以查看模型摘要,當然也可以省略
#檢視模型摘要
model.summary()
損失函數一樣用交叉熵,優化器我們用上面介紹廣泛用於深度學習中,且具有很好性能的Adam
#編譯模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
最後來訓練我們的模型看看準確率如何吧!
#訓練模型
model.fit(X_train, y_train, batch_size=128, epochs=20, verbose=1,validation_data=(X_test, y_test))
還記得第一次沒有升級的結果是200週期86%的準確率嗎?
第二次升級了激活函數還有學習率結果是20週期96%的準確率
結果這次跑到97%了!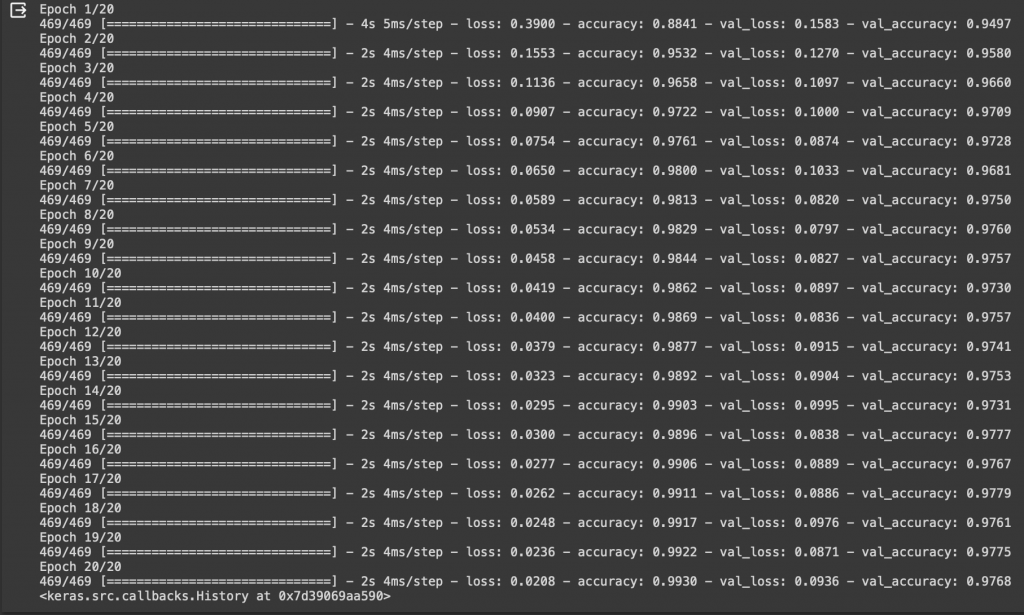
跑了那麼多次的手寫數字資料集,明天我們再來介紹其他不同的例子!


 iThome鐵人賽
iThome鐵人賽